Latest Business Blog Entries
We write idiomatic code
When we write Ruby code, we do it the Ruby-way. Same goes with Javascript
or Perl or Go. We read code a lot and know how to use language-specific benefits
and avoid the drawbacks. Our code is not different from any other code.
We follow Rails conventions
Ruby on Rails comes with its own set of assumptions and conventions (which
is why it is called opinionated). We are not only aware of these, but we
follow them in our everyday work. Recommended reading
The Rails 3 Way, Obie Fernandez.
We follow common styleguides
There are a couple of good styleguides around on GitHub and others. We
know them, we use them and we highly recommend them. Even to the point to
force ourselves by setting up these guides in our editors. For example
Styleguide for Ruby.
We use best practices
We visit conferences and read books to know how the good guys write code.
We listen to people telling us about not the better ways, but the best
ways to achieve our goals. Every day.
We read all the commits
It’s our codebase. We love it and we don’t want anyone destroying it.
This is why we read any commit coming in. I mean literally, every commit.
We do pair programming
If the issue to tackle is complicated, or we just want to talk to someone
while writing code, we simple ask anyone to join us in doing the work. Call
it 4-eye-principle, Wackeldackel or Rubberduck, it’s on our toolbelt, ready
to be used when needed.
We have a refactoring board, from which we pick regularly
Technical debt is everywhere. Our means to tackle this pile of guilt is
our refactoring board, which grows and shrinks, visible for each and everyone.
No process needed. There is always time to change existing and running
code. No broken windows allowed.
We use pull-requests to review code
We have a number of ways to push our code to the repository. Sending pull
requests is one of them. We ask others to take a look (or even ask ourselves
one day later), before we let it go into the wild. Simple and effective, if
needed.
We talk about our code
There’s a plethora of chances to talk about our codebase. Stand-ups,
coffee-times, ad-hoc discussions, lunchtime, and so on. Non-coders
disrespectfully shake their heads on us talking so much about our work.
We always talk about major code changes long before we implement them.
We know what everybody is working on
In order to avoid conflicts we tell others what we are working on. No
surprises, and no major merge conflicts. And even if we are working
in the same code area, we are able to handle any conflict showing up.
We know our co-workers
By working together every day, we know each others leanings, our strengths
and weaknesses. So we know when we have to support each other on tackling
complex problems and writing code. Even when someone tries something new
and experiments around, we trust what they are doing, because we know
they are doing right.
We seek code smells
Whenever we write code, we take a look around, identifying and marking
code smells. We utilize TODO, FIXME and QUESTION a lot, and find the time
to decover these spots and remove them.
We modularize our code
Even with all conventions, the codebase grows to a point where it is no
longer maintainable. We sport modules, mixins, concerns, gems, plugins,
packages. We know when to use inheritance and STI or composition. We do
this to remain focused on our given business case.
We test
A lot. All kinds of tests. Sometimes first and sometimes after we write
the actual code. No bug without adding a test. No refactoring without a test.
To write a test it to write code. We utilize test coverage, but 100% is
not our goal. That’d be insane. There’s a kind of test for each usecase.
We use the one most appropriate.
We struggle for fast tests
While writing tests is important, having a fast test suite is equally important.
Slow tests won’t be run, it’s simple as that. That’s why we observe the
trend on Jenkins (or Travis CI).
Every code change might have an impact. This is why we do log-jammin’.
We do it regularly and a lot. Logjam is a great tool for that.
We update
We not only keep our tools up-to-date, we keep the tiny bits of libraries
and packages up-to-date as well. We not only update gems mentioned in
the check-gem-versions build, we check for rarely used or development-only
gems as well.
We give back
Monkey-patching is easy. And dangerous. This is why we have a natural tendency
to return our code changes back to the original developers, in order to
improve their code and let ours grow smoothly and independently. We pullup
a lot.
We organize our codebase
Rails provides good means to organize the code. But that’s not sufficient.
There are authorizers, utilities, external APIs, decorators and so on.
And there’s a neat little place for all of them.

Back in Brighton, England for the dConstruct conference, after 2008 and 2010. If it wouldn’t be for the conference, visiting Brighton is worth all the time. Easy to get there (choose Gatwick Airport as your destination, and take the First Capital Connect train for 30 minutes), grab a bed in any hotel close to the beach and make your way around. It’s marvelous!
But the dConstruct conference is worth attending, too, and your time and money couldn’t be spent any more unrepentantly. I got repeatedly asked what the conference is all about, and to be honest, it’s not easy to answer. From what Clearleft and others state on its website itself, it is a collection (a smörgåsbord) “of clever clogs gathered together to twist our perceptions of technology and culture”. Yeah, that fits. It’s about technology for sure (lots of web developers and designers around), and it’s about culture as well, regarding all the Internet, but even more than that. It’s about how we see the world, what drives our motivation and inspiration. And anytime I get back home, I’m more focused and inspired than before. It’s about that, finding your place in the world around you.
It’s good to be back.
tl;dr
Validate your fixtures.
Details
As mentioned in our
Ploppcasts session about Testing
(German only, sorry) I'm using both fixtures and
factories when testing my Rails applications. One of the drawbacks from
using fixtures is that these don't have to be valid in terms of
ActiveModel validations.
In order to make sure my fixtures are in fact valid I introduced a fixtures test, which is simply
a unit test to automatically verify the fixtures' validity:
So, taken these fixtures:
the test will indicate one failure, because the fixture
user_without_email
is invalid. The fixture
invalid_user
won't be marked as failure, because its name is starting with
invalid_
telling the test that it should expect an invalid fixture, and
return a failure otherwise. By this, we can keep having even invalid fixtures
without failing tests.
tl;dr
Adding a to_s method to a Ruby class helps with debugging.
Details
I more and more tend to add to a Ruby class I want to test is a to_s method returning
some sort of information about the underlying object.
So whenever I have to dig a little deeper and have to debug code that uses an instance of
that class or I simply want to write some details to the logfile, I can use the returned
string and thereby make sure all relevant information is printed.
Returning only a hard-coded string or name doesn't make any sense at all though. So, let's
assume we have some sort of business object, for example a job doing some kind of work in
the background. It has a certain state which we want to know about:
If you put this into an application which keeps the waiting user up-to-date with the current
state of processing (as simulated below with a Ruby irb console), the user knows exactly
what's going on.
There are more methods a Ruby class should have. Make sure to take a look at Robert Klemme's
"The Complete Class" article.
I don't think a class should contain all of the methods described there, but it's a good starting
point.
tl;dr
While Rails having become faster from version 3.0 to 3.2 regarding most parts of it, it
actually became much slower when simply reading from the database.
Details
A couple of days weeks ago, when starting to switch over to Rails 3.1 from Rails 3.0,
our project
Sharesight
got slower and we simply couldn't find out what the reason was. Especially where my own
experience with Rails 3.1 was a good one, and most projects were at least a little bit faster
than running with Rails 3.0 . But not this time. We finally decided to start creating
new blank Rails apps, benchmark certain things and compare the results. And here we are now.
We created the GitHub repository
Simple Benchmark
and could reuse some of
TST Media's
groundwork, so we didn't start from scratch. The project consists of three
Rails apps, one based on Rails 3.0.12, one on 3.1.4, and finally one on 3.2.3,
the most recent stable one. We provided some tests with certain scenarios, which
we think are the most interesting: reading from and writing to the database, and
processing a couple of get requests (without database access). We wrapped it
all up in some benchmark reports, resulting in two charts.
The first chart shows four lines: reading from the database (blue line), writing to the database,
writing with some life-cycle hooks turned on, and finally writing with some validations
turned on. First surprise was that running validations (green line) took much longer, but maybe
it's because of the regular expression we were using.
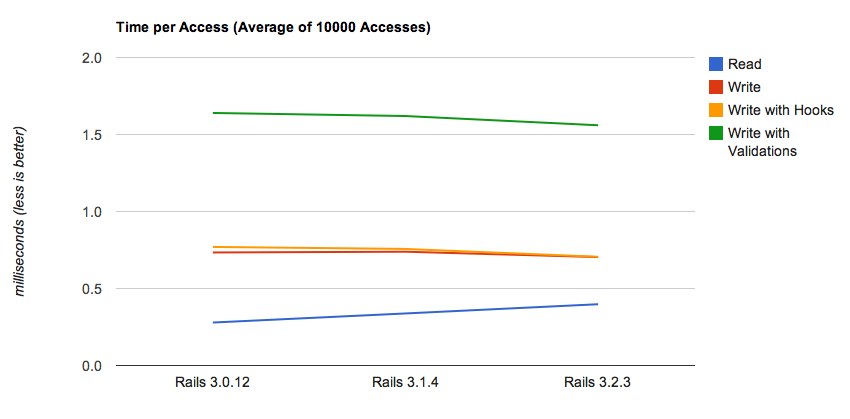
Chart 1: Accessing the database
But there's one more thing which actually comes as a surprise. All write requests
got slightly faster while moving up the Rails versions. But reading from the database
got slower. And it's actually much slower, it's more than 40% slower if you switch from
Rails 3.0 to Rails 3.2! This means that displaying content from the database got more
expensive, while writing to it was improved, which is a major point for most websites, I guess.
As you can see in the second chart, times improved from Rails 3.0 to 3.2, though being even
better in Rails 3.1. Rendering with partials (the yellow line) took - as expected - the
longest time to process.
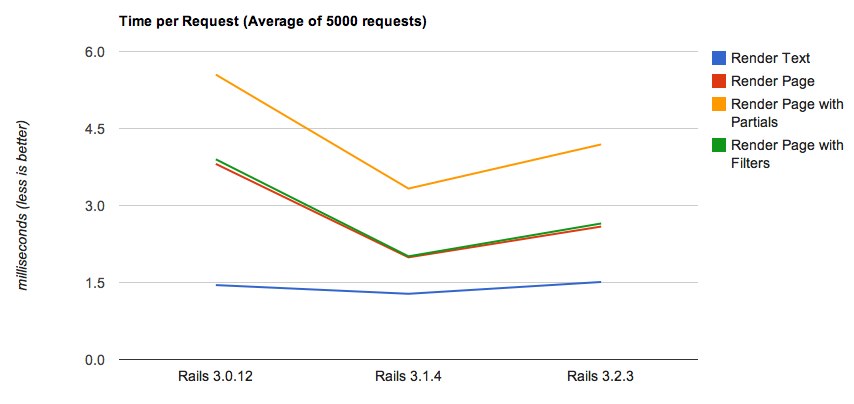
Chart 2: Rendering
So, what does this all mean?
For websites heavily reading from the database this is a major impact, since a surcharge
of 40% is quite a change to the worse. So if you have a lot of database selects per request
(actually hitting the database, not coming from any cache), you better start off optimising
your site before switching over to Rails 3.1 or 3.2 . We had an impact of around +25%
on our heaviest request, so we started optimising the processing time now.
Feel free to take a look at the
benchmarking setup
we chose. Any comment is appreciated!
Proud owner of a Señor Developer t-shirt. Thanks a lot to the guys from
Señor Developer.
If you wanna get one of those as well, visit their
Shop.

Taken with
Instagram
Let's say you have an attribute of an ActiveRecord object which is somehow calculated based on the state of the object,
and let's assume this calculation is really expensive in terms of performance. Then
calculate_until_saved
might be for you:
Here's the module which you can easily store under
lib/calculate_until_saved.rb

If you just want to know, who of the people you follow on
GitHub
started watching
a repository, or
started following
anyone, simply setup a task on
ifttt
and don't get all the noise provided by the GitHub activity feed.
How to set it up
1. Create a new task

2. Click on
this
and select the feed symbol

3. Then choose the trigger
New feed item matches
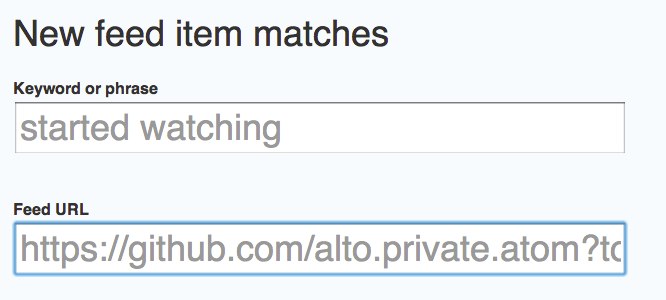
4. Complete the trigger fields by entering
started watching
and your activity feed url
https://github.com/alto.private.atom?token=...
5. Create the trigger by pressing the button and select a target by clicking the
that
link.

6. Click on the email icon for example

7. Then choose the trigger action again
Send me an email
8. And finally create the new action by pressing

9. Give your new task a nice description and create the task
 Finished!
Finished!
If you wanna know what I'm doing next, the answer is quite simple. Me and
my family are going down under for a while, at least one year, to Wellington,
New Zealand.
I will work for a small company named
Sharesight,
who make share portfolio management really easy. My responsibility will
be that of a senior Rails developer.
I'm really looking forward to this adventure!
More details to follow.

I just started a new project, and it’s called makemates!
I’m not yet telling what it’s all about, so stay tuned, and follow
@makemates on Twitter while waiting.
Older Posts are to be found in the archives...
